As a data management product, AccuRev’s foremost job is to provide a secure data repository for long-term storage of your organization’s development data. AccuRev’s implementation of the repository is straightforward and flexible, and key product features make it easy to protect the repository from accidental or malicious damage.
AccuRev has a simple client-server architecture. While the AccuRev Server (accurev_server) is running, it is the only program that accesses the data repository. This “single point of entry” to the repository makes it easy to enforce tight security at the operating system level.
|
•
|
a database called accurev, which contains:
|
|
•
|
a site schema, which contains the user registry, list of depots, list of workspaces, and other repository-wide information.
|
|
•
|
a schema for each depot, each of which contains depot-specific metadata and AccuWork issue records. (For licensing purposes, AccuRev’s issue management capability is termed “AccuWork”.)
|
|
•
|
the site_slice directory, which contains repository-wide AccuWork data, workflow configuration data, server preferences, and triggers
|
|
•
|
the depots directory, which contains a set of subdirectories, each storing an individual depot. A depot subdirectory stores one or both of:
|
|
•
|
a version-controlled directory tree: all the versions of a set of files and directories.
|
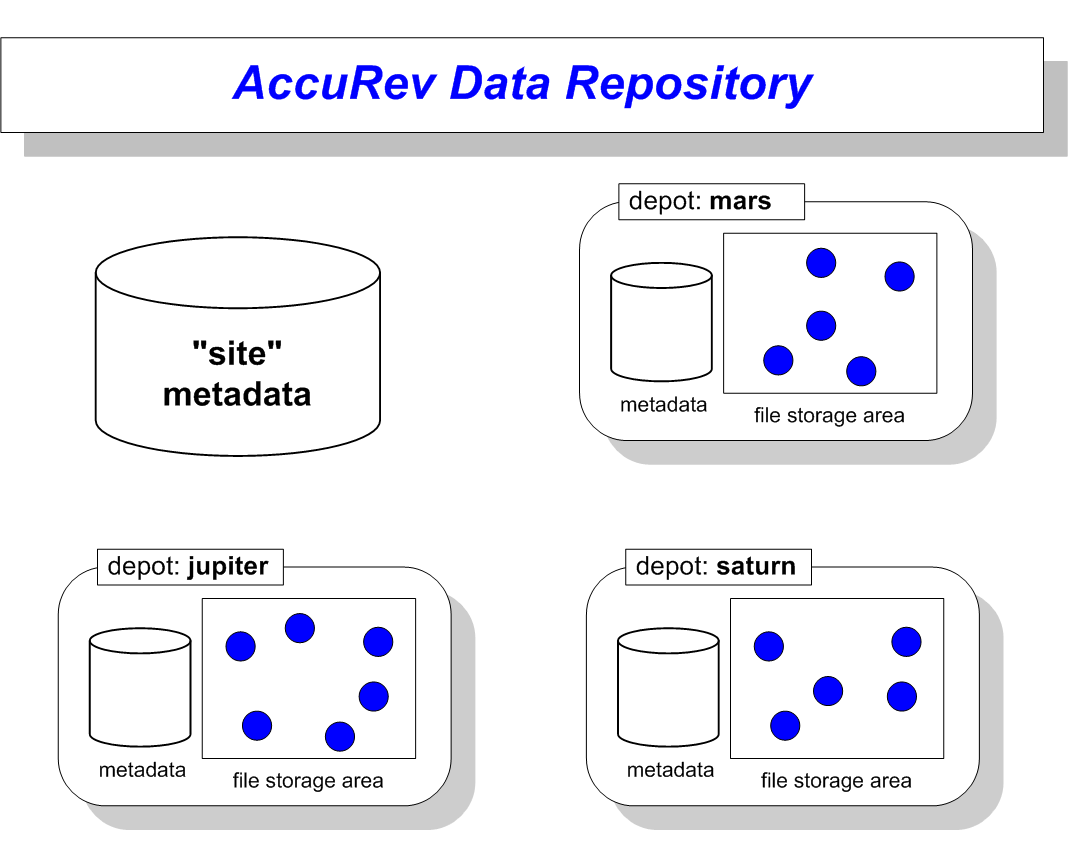
The illustration below shows the modular structure of the AccuRev data repository. Logically, the entire repository is located on the machine where the AccuRev Server program runs, but only the accurev database must physically reside on the server machine. The file storage areas — which typically are far larger than the databases and grow far faster — can be located elsewhere. For example, the file storage area of depot jupiter might be located on another disk on the AccuRev server machine, and the file storage area of depot saturn might reside within the local area network’s disk farm.
Note: when using the include/exclude (cross-link) facility, you can have a single depot serve multiple partially-independent or totally independent projects. See The Include/Exclude and Cross-Link Facilities on page 17.